The Birth of the Transformer Architecture
The birth of the Transformer architecture has completely rewritten the rules of the AI game. From ChatGPT to Sora, from AlphaFold to ViT, seemingly unrelated technological breakthroughs share the same DNA. This article will take you through the old world of RNNs and CNNs, revealing how the attention mechanism overcomes the challenges of long-range modeling and explores how this ‘relationship processing machine’ spills over from the language domain to reshape our understanding of the world.

Recently, I have been asked many times:
“How does ChatGPT actually work?”
Each time I want to answer seriously, but I don’t know where to start. Talking directly about neural networks is too abstract; discussing “large language models” feels like nonsense; when I mention Transformers, people usually nod politely and change the subject.
So, I decided to write this article.
Not to provide you with a technical manual, but to discuss something I believe many people overlook: Transformers are not just a neural network architecture; they represent a leap in thinking.
The ChatGPT you are using, the Sora-generated videos you see, and the AlphaFold that unravels the mystery of protein folding—all these seemingly unrelated technological breakthroughs share the same name.
In 2017, Google published a paper titled “Attention Is All You Need.”
This single paper rewrote the entire AI landscape.
Understanding it does not require you to write code or understand matrix operations. You only need to be willing to think clearly about one thing: Before the Transformer appeared, how did AI ‘read’ the world? What did it do right that made everything different?
This article will follow this line: the dilemmas of the old world → the core of the attention mechanism → two different missions → from language to everything → the cost of revolution and the future.
I will try not to make you feel like you are in class.
The Walls of the Old World: Before the Transformer
To truly understand a revolution, one must first feel how constrained the old world was before it was overthrown.
The ‘Reader’ with Amnesia
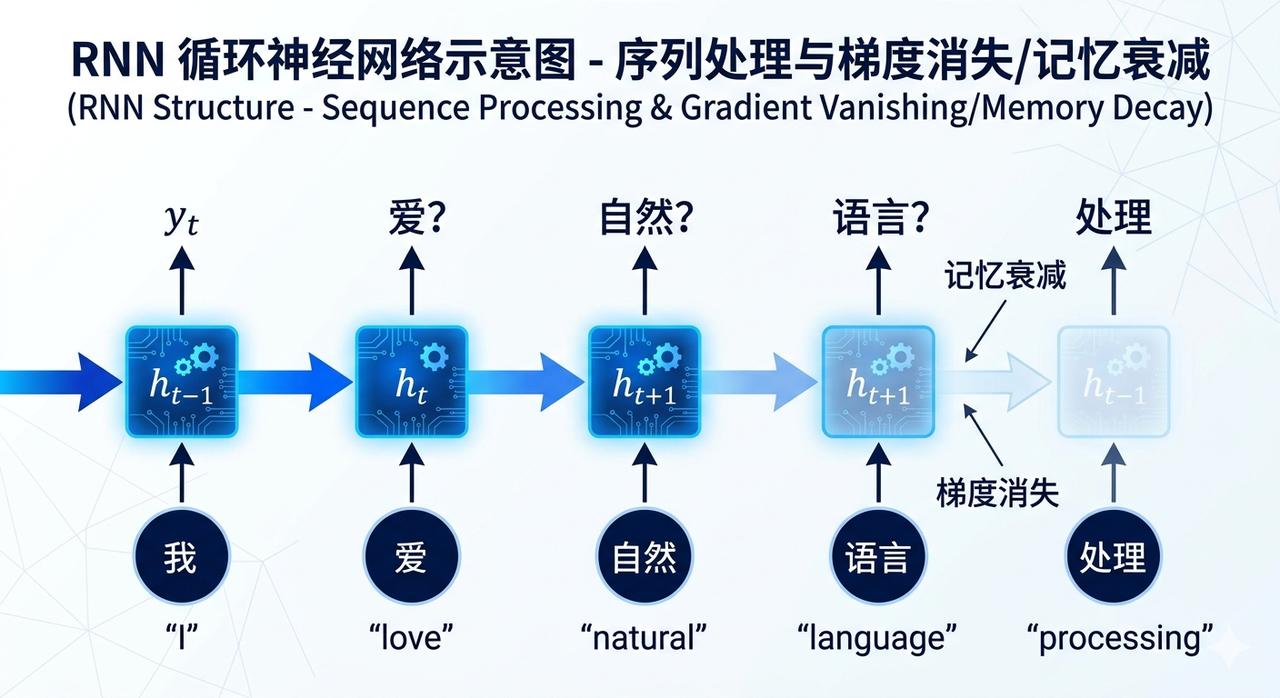
Before the Transformer emerged, the most mainstream tool for processing language was RNN (Recurrent Neural Network).
It worked in a strictly word-by-word manner.
Imagine a reader who can only see one word at a time. After reading it, they carry the “memory of that word” to the next word and continue. After reading the second word, they carry the “memory of the first two words” to the third word… and so on.
Sounds okay, right?
The problem is that this reader suffers from a peculiar form of short-term amnesia.
By the time they reach the 50th word of a passage, their memory of the first word has become blurred due to the subsequent 49 words’ “overwriting and dilution.” This is technically known as gradient vanishing—the signal diminishes layer by layer in the long sequence transmission, like a game of telephone, until almost nothing remains.
This leads to a very practical problem: the model cannot establish “long-distance dependencies.”
For example, in the sentence: “The cat, which had been sitting by the window all afternoon, finally fell asleep.”
The word “fell” should grammatically and semantically correspond to the initial “cat.” But for RNNs, the connection between “cat” and “fell” is severed due to the many intervening words. The model can only guess the next word based on the most recent words, with almost zero grasp of the overall logic.
Another critical issue is: Sequential dependence prevents parallel processing.
Since processing must be done word by word, the second word must wait for the first word to finish, the third word waits for the second… The entire computation process is a serial pipeline. No matter how powerful the GPU is, it cannot process all words simultaneously—it is forced to queue.
This is why training long texts with RNNs is both slow and ineffective.
Later, some attempted to patch this with LSTM (Long Short-Term Memory networks), trying to allow the model to “decide what to remember and what to forget.” It helped, but it was not a fundamental solution. The serial architecture problem remained, and the ceiling for long-range modeling was still there.
The Inspector with a Fixed ‘Observation Window’
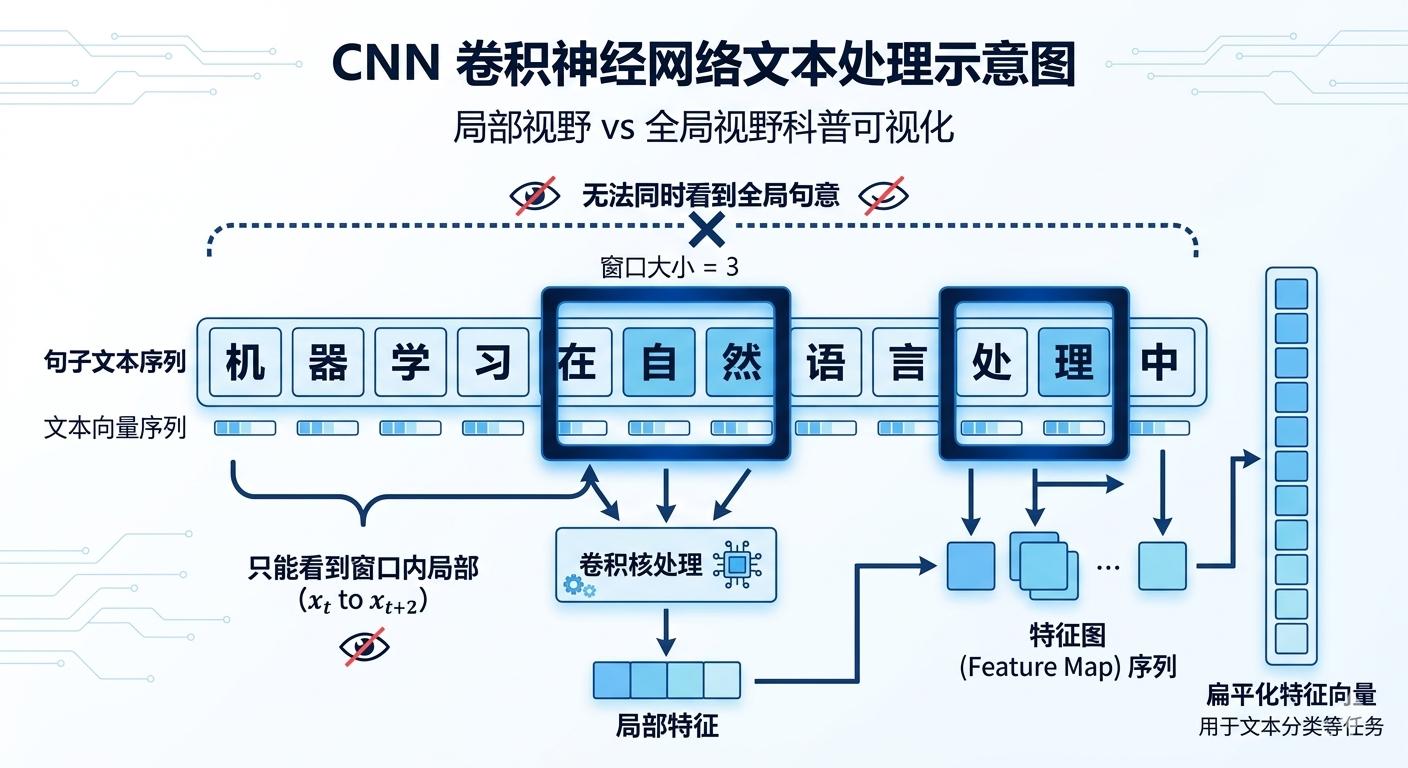
Another technical route used CNN (Convolutional Neural Network) to process language.
CNNs were originally powerful tools in the image domain. Their core operation involves using a fixed-size “convolutional kernel” that slides over the image like a scanner, capturing local features—such as edges, textures, and shapes.
Translating this logic to language means sliding a fixed-size “window” over sentences to capture local word group relationships.
But the problem is obvious: this window is fixed, and the field of view is limited.
Want to expand the “window” to see further word associations? You need to stack many layers, leading to an exponential increase in computational load, with unstable results. Worse, CNNs are inherently insensitive to positional order—they care about whether “there is a pattern in this area,” not about “the position of this word.”
Language is inherently about order; the phrases “I owe you” and “you owe me” contain the same words but convey entirely different meanings based on order. CNNs struggle with such nuances.
Thus, until 2017, the entire field faced the same wall:
Inefficient serial computation and the inability to model long-range dependencies.
It wasn’t that no one tried; it was just that the space for effort within this framework was becoming increasingly limited.
The Universe of Attention: What Transformers Did Right
The title of that 2017 paper, “Attention Is All You Need,” still reads like a declaration today.
It suggests: all your previous efforts may have gone astray.
Abandoning Order, Embracing the Global
The most fundamental decision of the Transformer was to completely abandon the sequential structure of ‘word-by-word processing.’
It no longer lets the model read one word at a time; instead, it processes all words in a sentence simultaneously. Each word is no longer a “link in a relay chain” but rather participants at the same table.
How radical is this change? To put it simply:
RNN’s method is like making you read a book from the first page to the last, and after closing the book, answering questions based on memory.
The Transformer method is like laying the book open in front of you, allowing you to see all pages at once and then answer questions.
Which method is easier for understanding the overall structure and long-distance connections of the book? The answer is obvious.
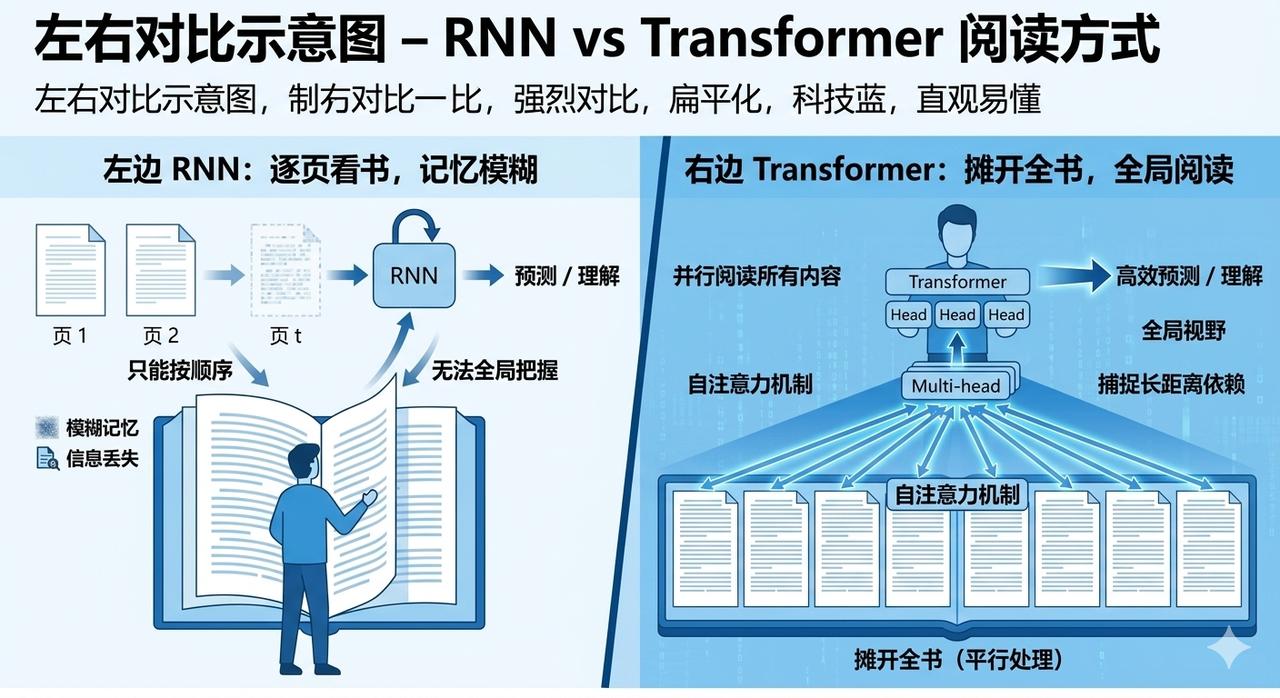
But this raises a question: how do these simultaneously appearing words know which ones are more relevant to each other?
This is what the Self-Attention Mechanism aims to solve.
Self-Attention: The ‘Internal Seminar’ of Each Word
Let me explain self-attention with a scenario.
Imagine an internal seminar at a company with the theme of “Reinterpreting Everyone’s Role in the Team.”
Each participant must do three things:
- Pose their own questions (Q, Query): “What information do I need from this team to redefine myself?”
- Show their labels (K, Key): “What can I provide? What are my expertise labels?”
- Prepare their content (V, Value): “If someone thinks I am relevant to them, what specific content can they obtain from me?”
Each participant takes their “question (Q)” and compares it with everyone else’s “labels (K)”: how well do your labels match my questions? Those with a high degree of relevance have a higher “weight” in my mind.
Finally, each participant aggregates everyone’s “content (V)” according to the weights—those with higher weights contribute more, while those with lower weights contribute less—to obtain a new self-representation.
This new self-representation has integrated the contextual information of the entire team.
Translating this back to language processing: each word in a sentence computes its relevance with all other words, and then redefines its meaning in that context based on the strength of the relevance.
This is why Transformers can handle long-distance dependencies—“cat” and “fell,” which are separated by many words, can establish a direct connection through self-attention without needing to relay through all the intervening words.
Multi-Head Attention: Simultaneously Hosting Multiple Seminars
Once you understand self-attention, Multi-Head Attention is easy to grasp.
Single-instance self-attention involves everyone discussing the issue on the same dimension. But language is multi-dimensional: a sentence contains grammatical relationships, semantic associations, referential relationships, emotional tendencies, and more simultaneously.
Multi-head attention operates by simultaneously hosting multiple seminars with different focuses.
The first seminar focuses on grammar, the second on semantics, the third on “who does ‘it’ refer to here”… Each seminar proceeds independently, and the conclusions from all sessions are combined to form a more nuanced and rich understanding of the sentence.
This is the meaning of “multi-head”—multiple attention “heads” capturing different dimensions of associations in parallel.
Positional Encoding: Injecting Order into Thought
But wait, there’s a question.
Since all words are processed simultaneously, how does the model know that “the dog bites the man” and “the man bites the dog” are two different sentences?
The cost of parallel processing is the inherent loss of awareness of positional order.
The Transformer’s solution is called Positional Encoding.
Before sending each word into the model, it is assigned a “positional coordinate”—this is the 1st word, this is the 2nd word, this is the 17th word… This positional information is encoded into a segment of numbers, which is added to the semantic information of the word before being sent into the model.
Thus, the model knows both “what this word means” and “what position this word is in.”
The difference between “dog” in the first position and “dog” in the third position is two different inputs for the model—despite being the same word.
The sense of order is thus “externally injected” into the parallel processing system.
The Foundation of the Structure: Residual Connections and Layer Normalization
Transformers not only have attention mechanisms but also two engineering designs that allow the entire architecture to be “deep.”
Residual Connections serve as a reminder: “No matter how complex your transformations are, don’t forget where you started.”
After each layer processes, the output of that layer is added directly to the input of that layer, ensuring that original information is not lost in the transformations. This design allows gradients to flow smoothly back to earlier layers, which is key to Transformers being able to stack dozens or even hundreds of layers.
Layer Normalization acts like organizing the data after each layer has processed—keeping the data distribution stable across layers to avoid situations where some values explode while others vanish. It makes the training process smoother and converges faster.
These two designs are the foundation that supports the “thinking tower” of the Transformer to be built high and stable.
Twin Engines: The Philosophy of Encoder and Decoder
Understanding the attention mechanism leads to the next question: how are these mechanisms combined to perform different tasks?
The answer lies in the two core components of the Transformer: Encoder and Decoder.
Encoder: The Omniscient ‘Reviewer’
The task of the encoder is extreme understanding.
Given an input text, it uses bidirectional self-attention—looking at both the preceding and following context—to compress the meaning of the entire text into a rich contextual vector representation.
To illustrate: the encoder is like someone who has completed an entire project and sits down with all the materials to review. They do not start outputting conclusions while reading the first document; they form a complete judgment about the meaning of each document after reviewing all materials.
This “omniscient” perspective makes the encoder very adept at tasks requiring deep understanding:
- What is the emotional tendency of this sentence?
- What word should fill in the blank in this text?
- Are these two sentences similar or contradictory?
BERT is a representative model of a pure encoder architecture. Google refreshed almost all benchmark tests in the NLP field with it because it can truly “understand” the deep meaning of input texts.
Decoder: The Strictly Causal ‘Impromptu Speaker’
The task of the decoder is sequence generation.
However, it has a strict limitation: when generating the N-th word, it can only see the previously generated N-1 words and must not peek at the content that has not yet been generated.
Why this limitation? Because in a real generation scenario, the subsequent words do not yet exist—the model generates word by word, basing each step on the history already established. Allowing it to “peek into the future” would be cheating during training.
This limitation is technically implemented through masked attention—forcing future words to be obscured so that the model cannot see them.
Imagine an impromptu speaker wearing a blindfold who can only see to the left. They do not know what they will say next and can only proceed word by word based on what has already been said. Yet they can still tell a logically coherent story—because they are making the most reasonable next prediction at each step.
GPT series is a representative of pure decoder architecture. The logic behind ChatGPT is essentially that of a highly trained “next word predictor.” Each time it responds to you, it repeatedly asks itself: “Based on everything so far, what is the most reasonable next word?”
Encoder-Decoder: The Professional ‘Translator’
When the encoder and decoder are combined, they form the complete architecture originally described in the Transformer paper.
The workflow is as follows: the encoder first comprehends the entire source sequence (for example, a sentence in Chinese) and generates a complete understanding representation; then the decoder takes this representation and, under its guidance, generates the target sequence (for example, the corresponding English translation) one word at a time.
During each generation step, the decoder not only looks at the words it has generated but also queries the encoder’s output through cross-attention: which information from the source sequence is most relevant to the current word being generated?
This is a truly meaningful “understand first, then express” process.
T5 and BART are representatives of this architecture. They excel at tasks requiring “precise transformation”: machine translation, text summarization, question-answering systems… first thoroughly understanding the source language, then accurately expressing it in the target language.
Paradigm Overflow: From Language to All Sequences
At this point, the core logic of Transformers has been clarified.
However, I believe what truly makes this architecture extraordinary is not how powerful it is in the language domain, but a deeper insight hidden behind it:
The essence of Transformers is processing “sequential relationships.” Mathematically, everything can be represented as a sequence.
Once you accept this perspective, its application boundaries begin to expand at an unexpected speed.
Images: ‘Reading’ a Photo as Text
In 2020, Google proposed Vision Transformer (ViT), doing something that sounds a bit strange:
It cut an image into 16×16 pixel-sized patches, arranged these patches in order, and processed them using the exact same Transformer architecture.
Each patch is like a “word.” The entire image becomes a “sentence.”
As a result, this approach outperformed the CNN architecture that had dominated the image domain for a decade in large-scale image classification tasks.
This is quite interesting—it’s not that CNNs are bad, but rather that the “attention” logic of Transformers is much more broadly applicable than we thought. It uses the same mathematical structure to process the semantic relationships between “dogs” and “cats” as it does to process the spatial relationships between the upper left and lower right corners of an image.
Proteins: Unraveling a Half-Century Biological Mystery
I believe this application case is the most far-reaching impact of Transformers spilling over from the language domain.
Proteins are composed of chains of amino acids. Given an amino acid sequence, what shape will it fold into in three-dimensional space? This shape determines the protein’s function and is the core basis for drug design and disease research.
This question has been studied by biologists for 50 years without a reliable computational prediction method.
AlphaFold 2’s core is to treat the amino acid chain as a sequence and use the attention mechanism of Transformers to learn the spatial relationships between amino acids—what two amino acids are close to each other in three-dimensional space, and which regions will form helical structures.
Its prediction accuracy has reached the level of experimental measurements.
The scientific community has called this breakthrough “one of the most significant biological advances in 50 years.”
A mathematical framework originally designed for language translation has unraveled a half-century biological mystery. This alone is enough to leave one speechless for a moment.
The Bigger Picture
Today, Transformers or their variants have appeared in code analysis, audio generation, video understanding, molecular design… in almost every AI application field you can think of.
I believe this is not just a story of “a technology being very useful.” It indicates that we may have found a sufficiently low-level mathematical language capable of describing the “relationship structures” between different modal data.
Language is a relationship. Images are relationships. The spatial structure of proteins is a relationship.
Everything is a relationship, and Transformers are precisely a machine for processing relationships.
The Cost of Revolution and the Dawn of the Future
No revolution comes without a price.
Transformers have brought a paradigm shift but also two significant costs.
Data Hunger and Computational Black Holes
Data hunger.
The capabilities of Transformers come from pre-training on massive amounts of data. The training data for GPT-3 exceeds 450 billion tokens, which is roughly a substantial slice of all indexable internet text.
Even more concerning is that as the data scale increases, models exhibit what is known as “emergent abilities”—some new capabilities suddenly appear after reaching a certain scale threshold, rather than growing linearly. This means that to achieve qualitative change, you must first endure a massive quantitative change.
This itself is a monopolistic barrier. Only a few organizations globally can acquire, clean, and process internet-scale data.
Computational black holes.
Training a model at the level of GPT-4 is estimated to cost over 100 million dollars, consuming enough electricity to power a small city for weeks.
“Anyone can train a large model”—this statement is almost a joke under today’s Transformer architecture. The concentration of computational power is locking cutting-edge AI research behind the walls of a few super companies.
Architecture Evolves, Bottlenecks Loosen
Fortunately, this field has never lacked smart people looking for solutions.
Mixture of Experts (MoE) architecture is currently the most mainstream direction for efficiency breakthroughs. The core idea is: do not let all parameters participate in every computation; instead, divide the model into many “expert groups,” activating only a few that are most relevant to the current task.
DeepSeek V3 is a milestone case in this direction—using relatively fewer active parameters to support a total parameter count in the hundreds of billions, significantly reducing training costs.
Optimizations of attention mechanisms are addressing another bottleneck: memory and computational overhead for long sequences. Standard self-attention has a computational complexity that grows quadratically with sequence length—doubling the sequence quadruples the computational load. Techniques like MLA (Multi-Head Latent Attention) and sliding window attention attempt to flatten this growth curve.
There are also more radical explorations of new architectures. Mamba and other state-space models (SSM) are trying to maintain the modeling capabilities of Transformers while reducing the complexity of processing long sequences to linear levels. Currently, their hybrid architectures with Transformers have shown promising potential in some tasks.
All these efforts point to the same goal: to make powerful models no longer just toys for a few.
A Perspective Worth Considering
I want to present a somewhat disruptive perspective here.
Many of the AI application paradigms we discuss today—RAG (Retrieval-Augmented Generation), Agents, various tool invocation frameworks—what are they essentially?
They are compensating for the current limitations of model capabilities.
RAG exists because the model’s context window is not large enough, and memory is not long enough; the Agent framework is needed because the model’s single-step reasoning ability is limited and requires breaking tasks into multiple steps; tool invocation is necessary because the model lacks real-time access to external information…
This is not a criticism of these technologies—they are clever and necessary engineering solutions under today’s conditions.
But it implies that as the foundational capabilities of Transformers and their successors continue to enhance, the forms of these upper-level structures will continue to evolve, and some may even disappear.
When the model’s context window expands to a sufficient length, and reasoning capabilities become strong enough to reach a certain threshold, many application paradigms we take for granted today may be rewritten.
This is not a bad thing. This is how the entire ecosystem rearranges itself after foundational capabilities improve.
Epilogue: Understanding the Grammar of This Era
In 1665, Newton discovered gravity.
For the next two hundred years, whether calculating planetary orbits, designing bridges, or understanding tidal fluctuations, physicists used the same mathematical language—because it was sufficiently low-level to describe a wide range of phenomena.
I sometimes wonder if Transformers are playing a similar role.
Not because they are perfect, but because they touch upon something deeper: defining meaning dynamically through ‘relationship strength’ and replacing ‘sequential memory’ with ‘global associations.’ This logic holds in language, in images, in protein folding, and in code.
When an architecture can simultaneously understand language, images, protein folding, and musical rhythms, are we approaching a kind of unified intelligent grammar?
I do not know the answer.
But I feel that in this era where AI is rewriting almost all industry rules, understanding what Transformers are doing should not be the exclusive domain of engineers.
It is the meta-model of our time.
Understanding it is understanding the grammar of this era.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.