Gaode Unveils ABot: The World’s First Full-Stack Embodied Technology System for AGI
On April 19, 2026, at the Beijing Yizhuang Robot Half Marathon, Gaode, a subsidiary of Alibaba, officially unveiled the world’s first fully autonomous embodied robot, “Gaode Tutu.” This quadrupedal robot successfully assisted visually impaired individuals in navigating complex obstacles and crowds, bridging the technological gap between laboratory settings and open environments.

The foundational technology enabling Tutu to handle demanding scenarios such as guiding the visually impaired is Gaode’s newly released ABot full-stack embodied technology system. This system efficiently transforms Gaode’s accumulated spatial intelligence assets into core training resources for embodied systems, based on thousands of real-world scenarios and millions of multimodal Clip data, making it the first full-stack embodied technology system aimed at AGI globally.
ABot System: Three-Layer Flywheel Design for Continuous Evolution of Embodied Intelligence
The ABot system employs a closed-loop flywheel design encompassing three layers: data, model, and application. Its architecture is not merely a simple stack but deeply interlinked, functioning as a unified system where “data drives models, models serve applications, and applications feedback into data.” This approach effectively addresses three major industry bottlenecks: data scarcity, simulation gaps, and skill generalization, forming a complete self-evolving loop.
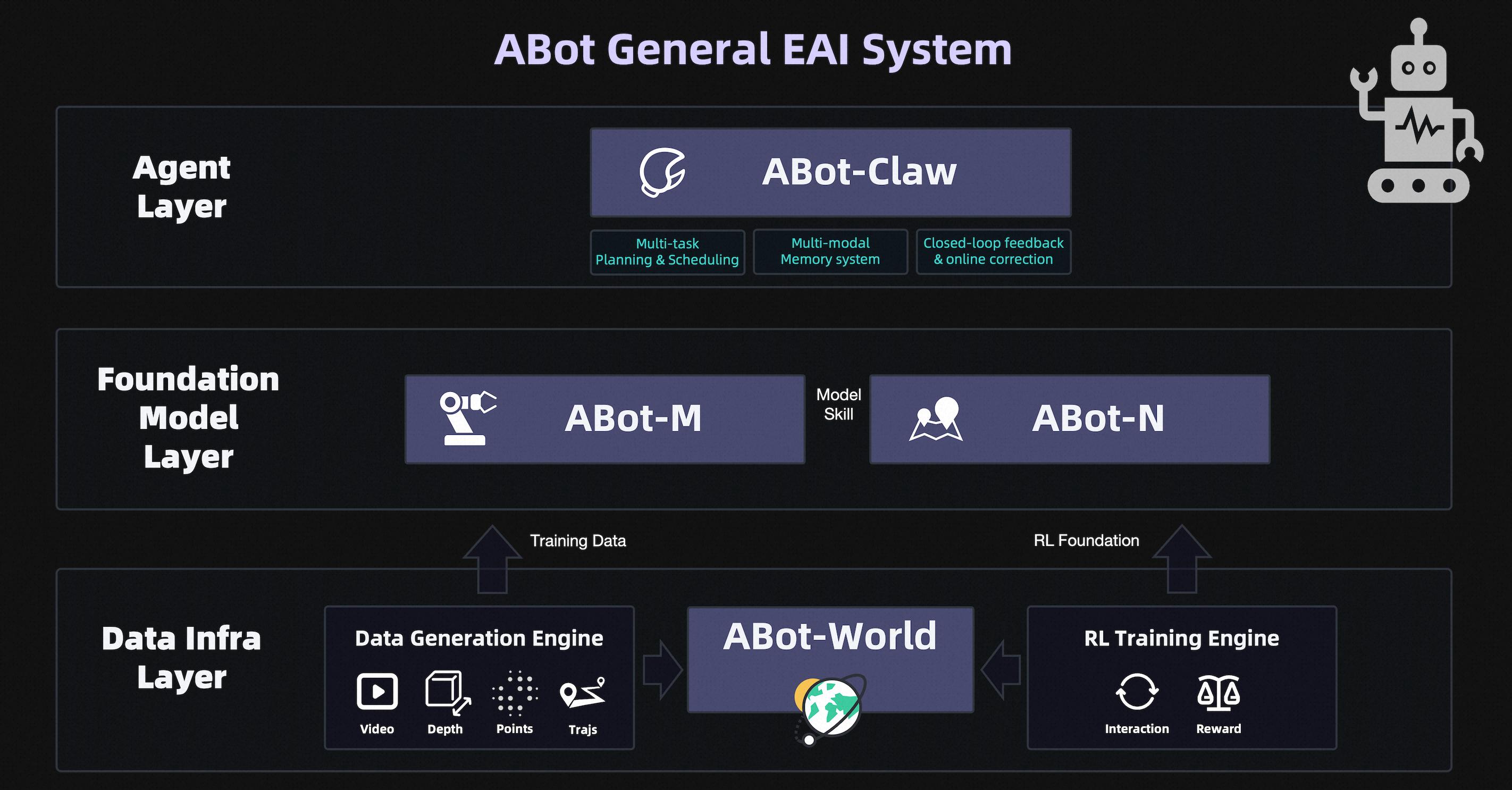
Data serves as the core “fuel” for embodied intelligence, directly determining its generalization capabilities. Unlike large language models, traditional real-world data collection is difficult to scale and incurs exponentially rising costs.
As the core of the data layer, ABot-World synthesizes four types of training data—Video, Depth, Point Cloud, and Trajectory—in bulk, combined with a Reinforcement Learning Training Engine that defines rewards and penalties in virtual environments, allowing for iterative learning. The model uses high-fidelity simulations to replace costly real-world data collection, fundamentally bridging the Sim-to-Real gap and compressing data costs by several orders of magnitude.
The model layer focuses on the generality of embodied operations and long-range navigation, with ABot-M responsible for operations and ABot-N for navigation. These two models are trained separately and can be combined through a Model Skill mechanism to accomplish complex long-range tasks.
The application layer centers around the embodied version of “Lobster,” ABot-Claw, which unifies heterogeneous robots under a shared cognitive framework, creating an “execution hub” with scheduling, memory, hierarchical control, and social alignment capabilities to address challenges like long-range task loops and knowledge sharing.
The design logic of the ABot system directly follows Gaode’s spatial intelligence flywheel: leveraging nearly a billion monthly active scenarios to generate massive spatiotemporal data and real-time feedback, the algorithms continuously iterate in a closed loop, deepening the model’s understanding of the physical world. The flywheel evolves daily in real-world settings, fundamentally defining Gaode’s systematic advantages: relying not on singular technological breakthroughs but on the continuous operation of the flywheel in real scenarios.
ABot-World: Leading in Physical Compliance, Action Controllability, and Zero-Shot Generalization
While mainstream world models still struggle with “visual illusions” and disconnections in dynamics, ABot-World has made significant breakthroughs, becoming the first globally to deeply embed physical laws into a differentiable and evolvable dynamics engine throughout the generation process. As the foundational simulation base of the ABot system, it directly determines the physical consistency and generalization limits of upper-layer models, enabling a complete closed loop from “virtual training to real deployment.”
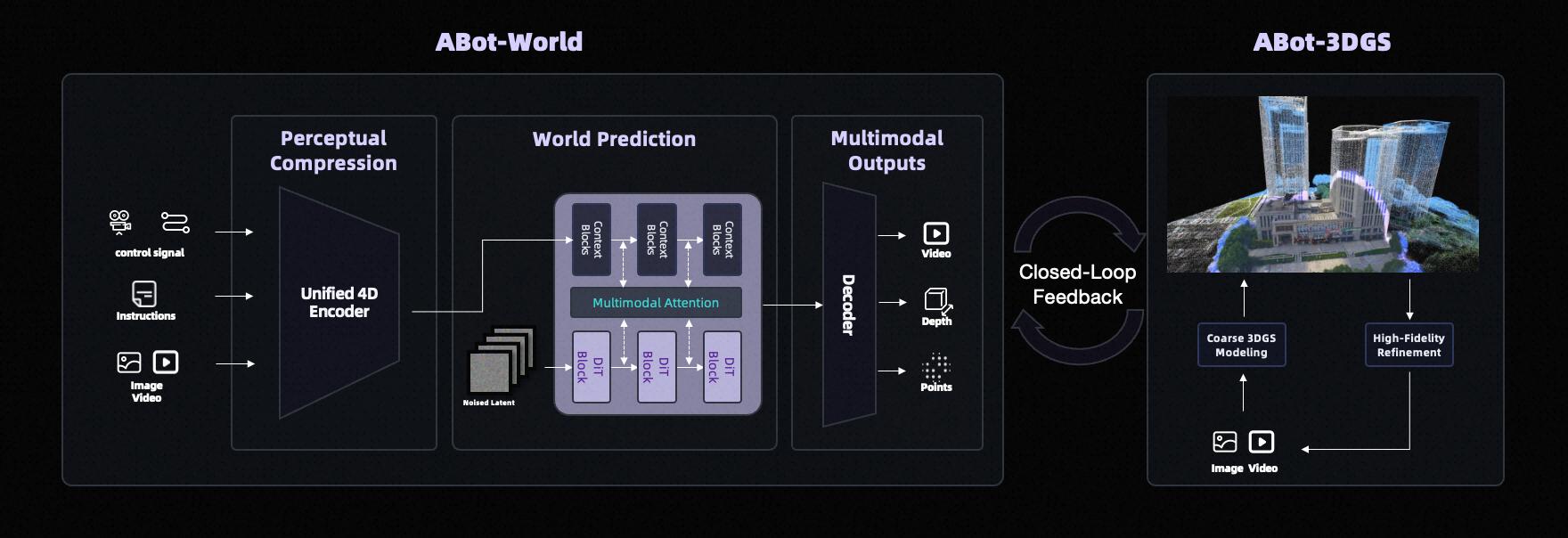
Architecturally, ABot-World is designed specifically for embodied intelligence with a 14B DiT architecture, generating future state sequences that conform to spatiotemporal dynamics from observations and actions as inputs. It leverages millions of real data points and multi-level sampling governance to break through the constraints of single-task generalization.
In scene construction, the 3DGS cold-start spatial base targets sparse inputs from mobile photography and aerial mapping, transforming low-quality videos into high-quality 3D scenes through an automated process of “rough modeling, high-fidelity restoration, and distillation loops,” significantly lowering data costs.
In training, the model introduces a Diffusion-DPO physical preference alignment framework, generating a list of physical rules via VLM and independently discerning them to create good and bad sample pairs, driving the model to actively suppress behaviors that violate physical laws. The integration of Lagrangian dynamics with 3DGS reconstruction ensures that each frame is a differentiable physical snapshot containing attributes like mass, friction, and contact forces.
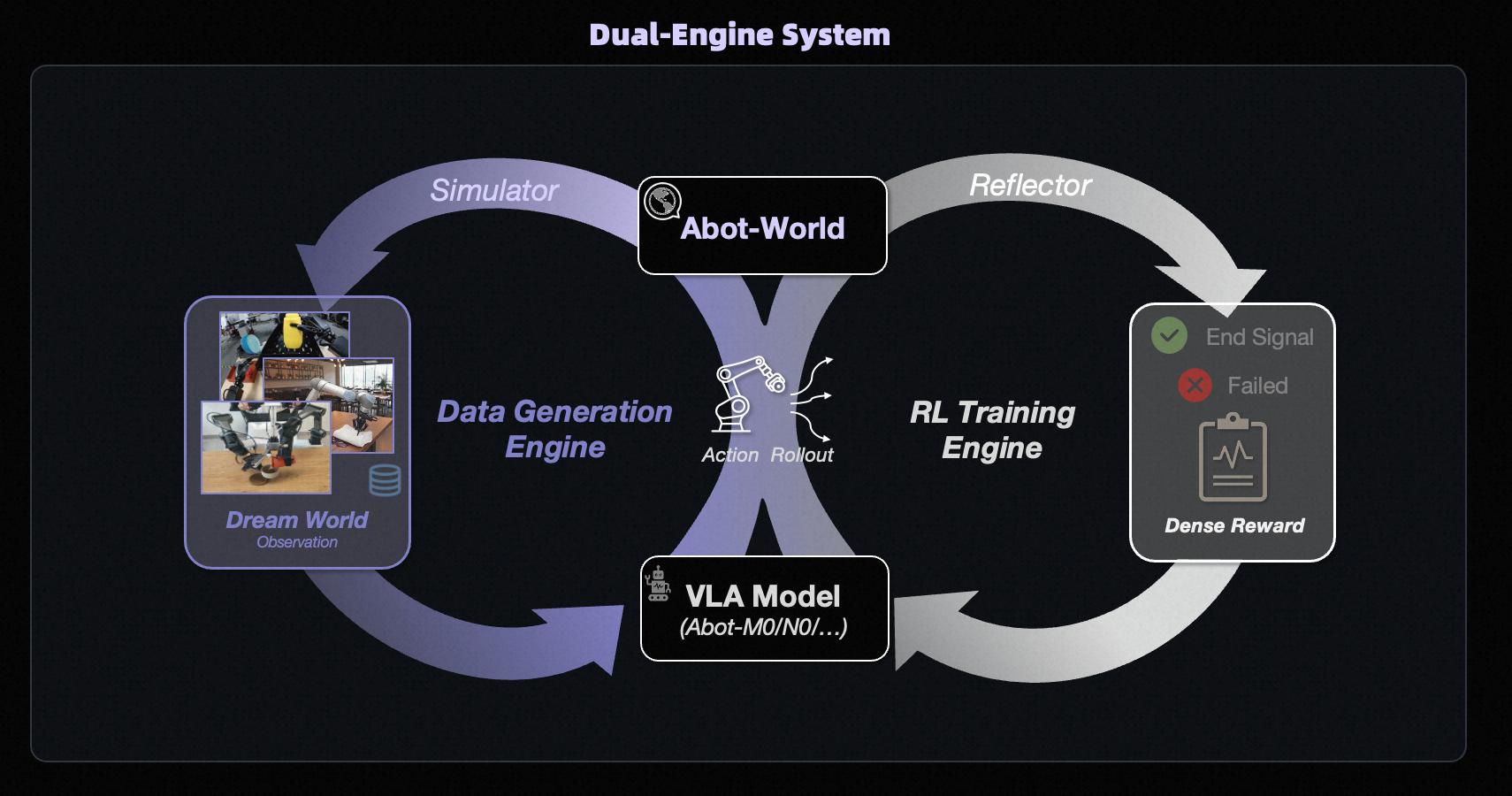
Additionally, ABot-World has established a parallel architecture of “training + data” dual engines, achieving model self-evolution. Relying on proprietary maps and anonymized data, combined with 3DGS technology, it has achieved centimeter-level reconstruction and lighting consistency, producing over ten thousand 3D real scenes, millions of inference data, and tens of millions of training trajectories, covering 99% of typical life scenarios. By integrating with the VLA closed loop, the model realizes continuous evolution through “prediction as training, practice as learning,” and supports precise control across various mechanical forms through cross-modal action mapping.
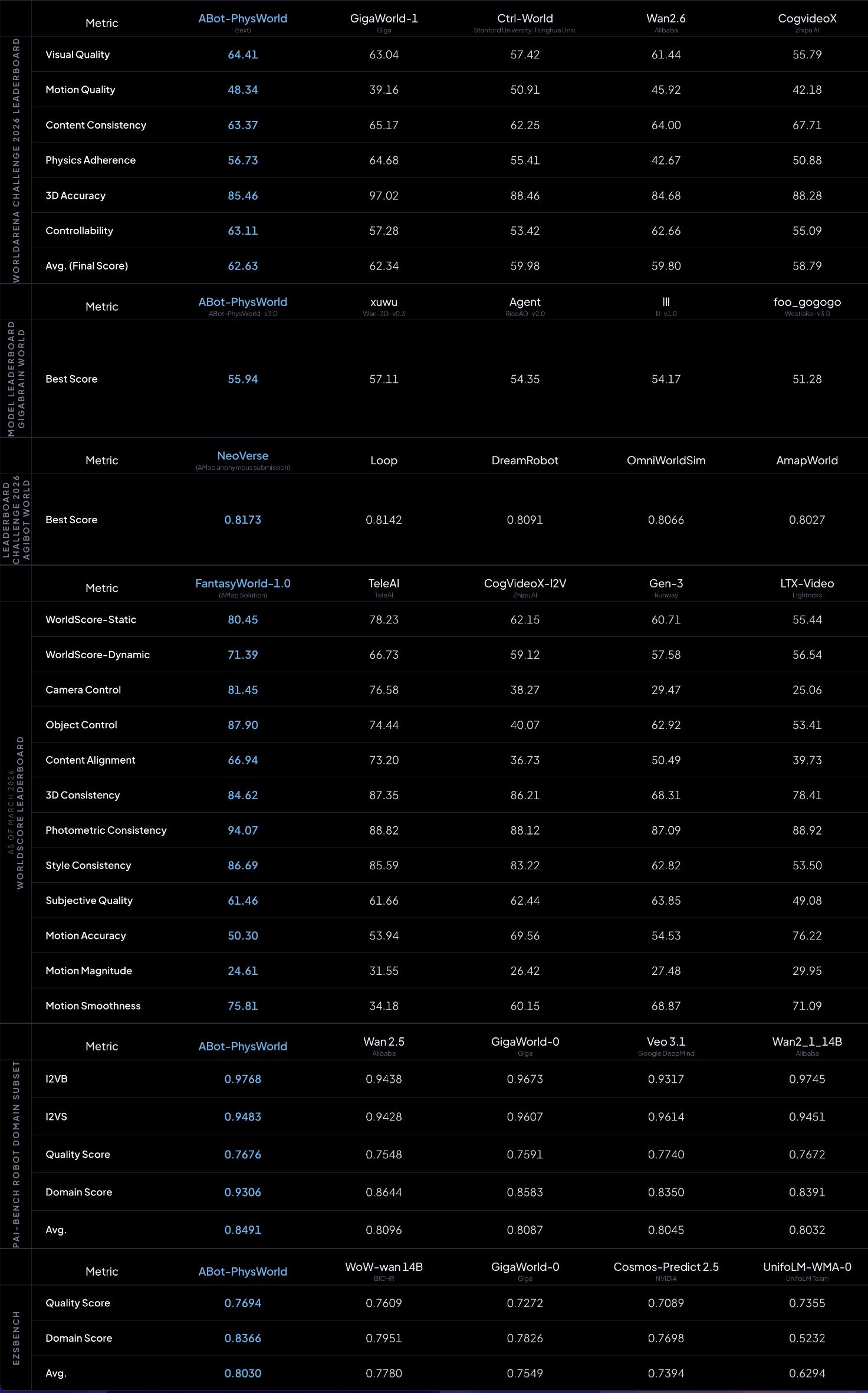
In mainstream evaluations such as PBench, EZSbench, WorldArena, and Agibot World Challenge, ABot-World consistently leads, becoming the only model to achieve SOTA in physical compliance, action controllability, and zero-shot generalization across three dimensions.
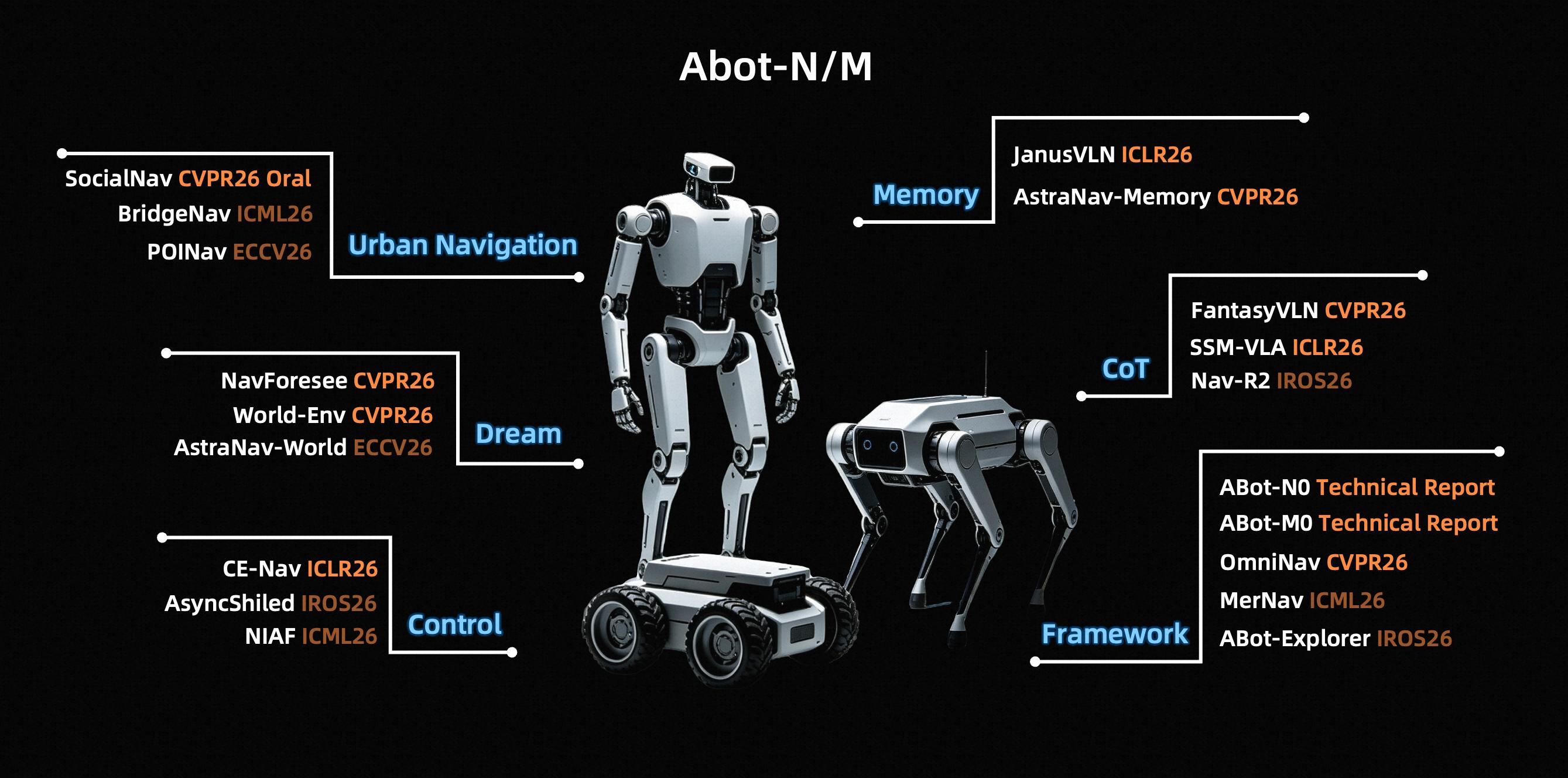
ABot-N & ABot-M: The “Dual Core of Motion” in the ABot System Achieving 11 SOTAs
If the ABot full-stack system is viewed as the “operating brain” of embodied intelligence, ABot-N and ABot-M serve as its “dual cores of motion,” managing the robot’s “legs” and “hands,” respectively, directly responding to the fundamental instructions of “where to go” and “what to do” in the physical world. Leveraging a unified architectural design, Gaode has created a decoupled and collaborative dedicated base model, breaking through the technical bottlenecks of cross-form adaptation and cross-task generalization.
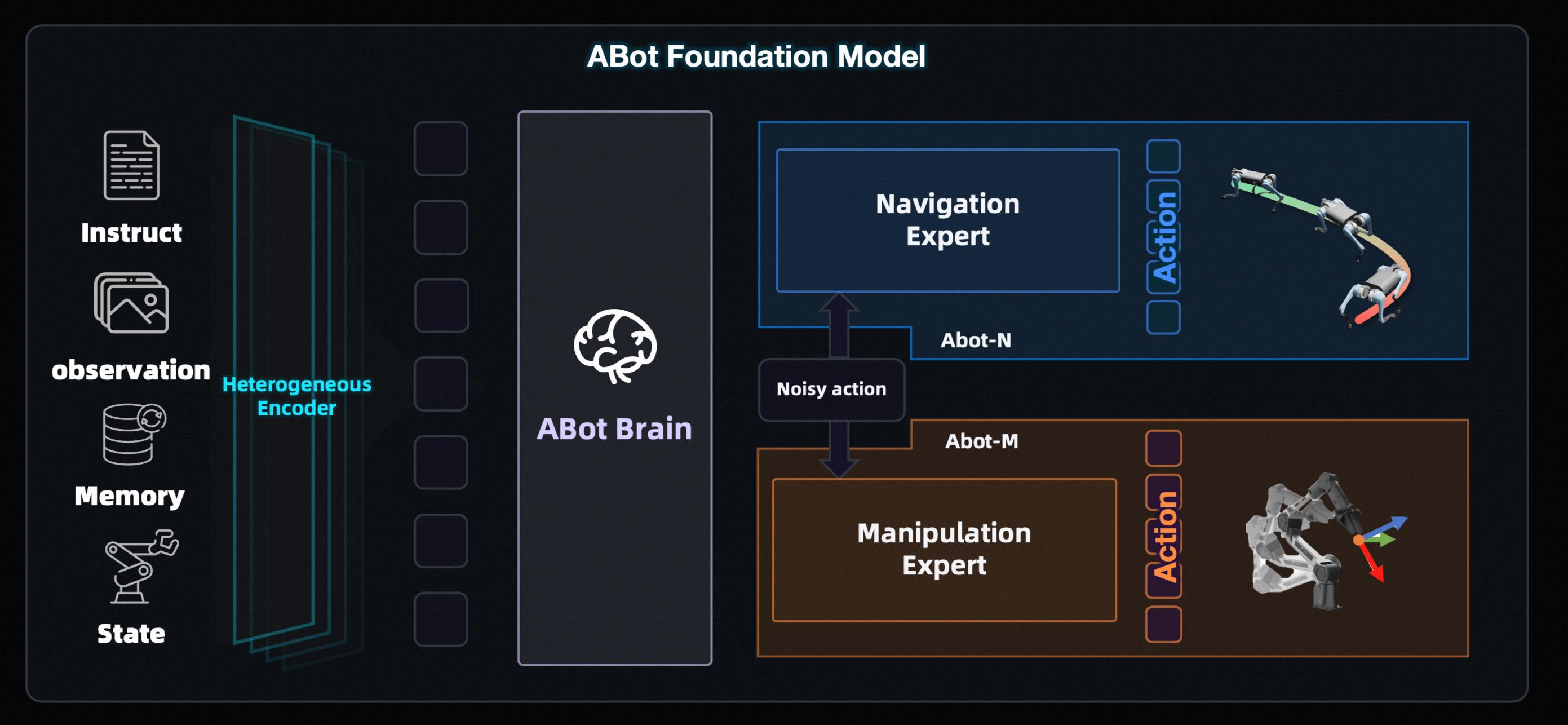
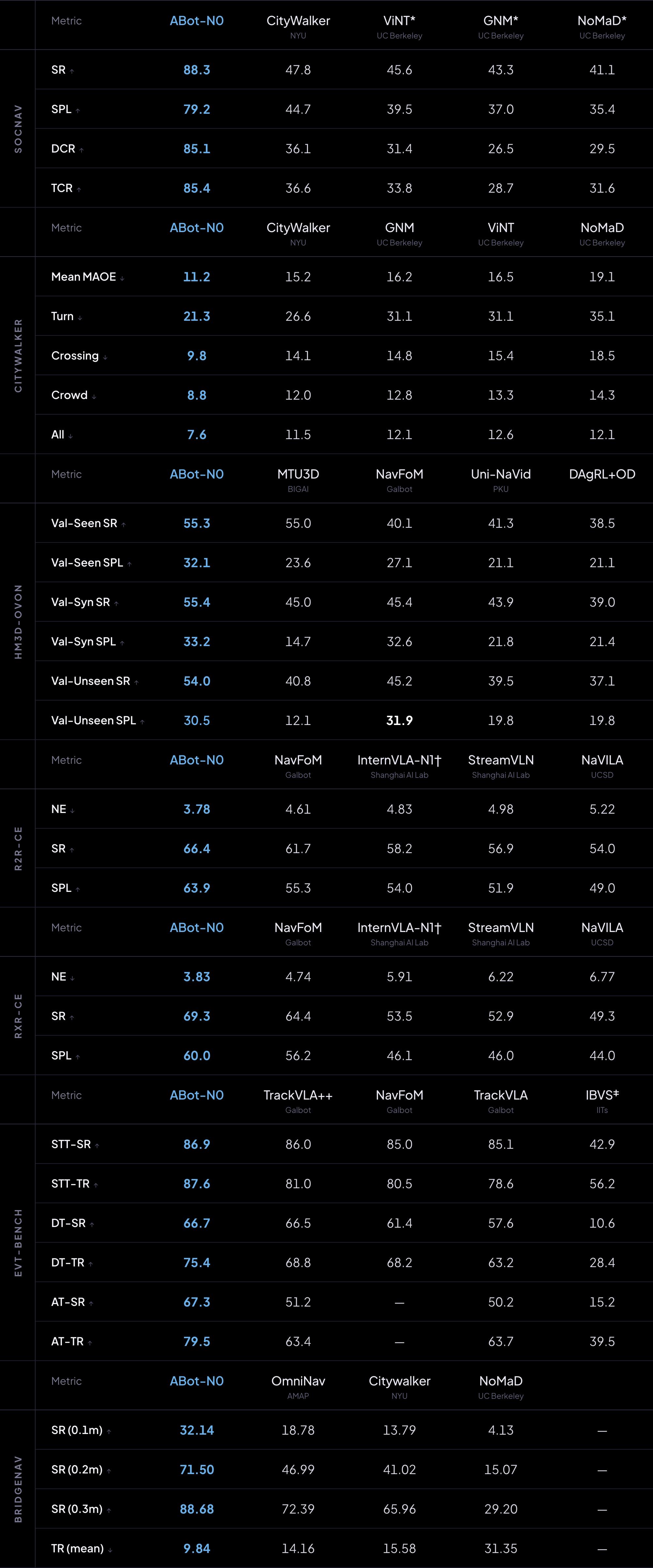
As the world’s first VLA base model to achieve unification in five core navigation tasks, ABot-N possesses intent understanding, autonomous decision-making, and continuous evolution capabilities, serving as the core navigation engine for Tutu’s transition to an open world. It employs a hierarchical “brain-action” architecture, achieving full coverage of single model navigation tasks through multi-module collaboration, completely breaking the generalization ceiling of traditional dedicated architectures.
After its launch, ABot-N rapidly refreshed SOTA across seven authoritative benchmarks, including VLN-CE (R2R/RxR), HM3D-OVON, and EVT-Bench, demonstrating significant advancements in navigation accuracy, social compliance, and zero-shot generalization.
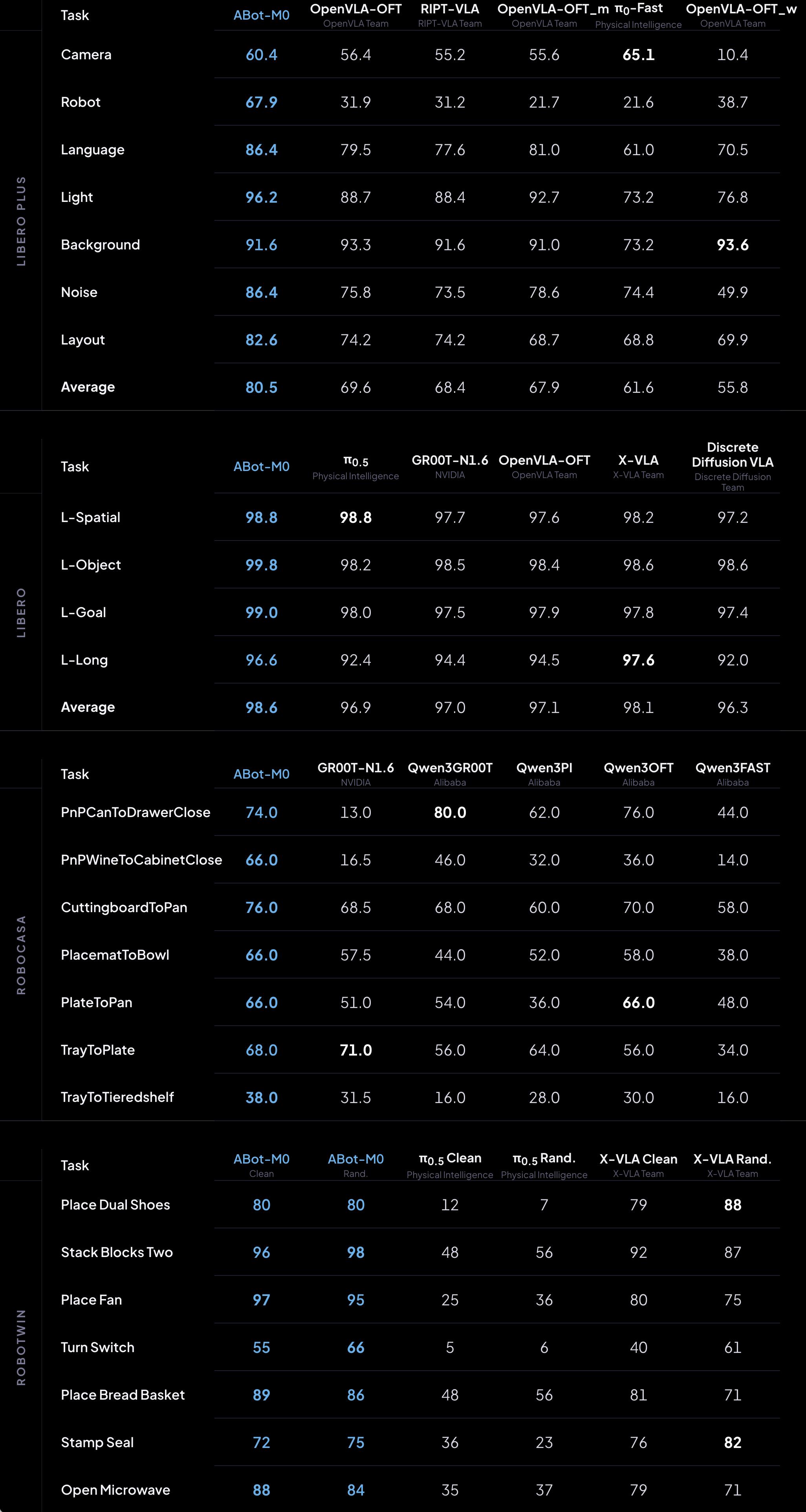
ABot-M is the world’s first unified architecture for embodied operation base models, capable of adapting a “general brain” to various robotic forms, significantly enhancing the operational model’s generalization capabilities across heterogeneous robotic forms and task scenarios.
ABot-M introduces the world’s first action manifold learning, shifting the learning objective from denoising reconstruction to manifold projection, greatly improving the stability and decoding efficiency of action generation, showcasing stronger scalability in complex scenarios such as high-degree-of-freedom full-body control. Additionally, it employs a dual-stream architecture of semantic flow and action flow at the perceptual end, enhancing the execution accuracy of fine operations.
In mainstream evaluations such as LIBERO, LIBERO-Plus, RoboCasa GR1, and RoboTwin 2.0, ABot-M has significantly surpassed strong baselines like π0.5, UniVLA, and OpenVLA-OFT, achieving systematic leadership in generalization capability, robustness, and cross-form transfer.
Moreover, multiple sub-results from ABot-N and ABot-M have been selected for top conferences such as ICLR and CVPR, becoming reference paradigms for precise, efficient, and safe robotic navigation and operation.
ABot-Claw: Innovating the “Map as Memory” Generalized Centralized Harness Architecture
Memory is the foundational cornerstone for robots to bridge the gap between cognition and execution. Traditional machine vision is limited by the notion that “beyond the field of view is a wasteland,” leading to fragmented memory that severely restricts generalization capabilities.
To overcome this bottleneck, ABot-Claw introduces the “Map as Memory” concept, reconstructing the memory mechanism of embodied intelligence. As the “execution hub” of the ABot system, ABot-Claw adopts a centralized Harness architecture, setting Gaode maps and user private maps as global cognitive anchors, unifying multimodal perception data into a shared semantic space, forming a dynamically refreshable and persistently retained “world memory.” New terminals can inherit environmental cognition at zero cost by merely reading the global context, completely shattering the isolation of scenes.
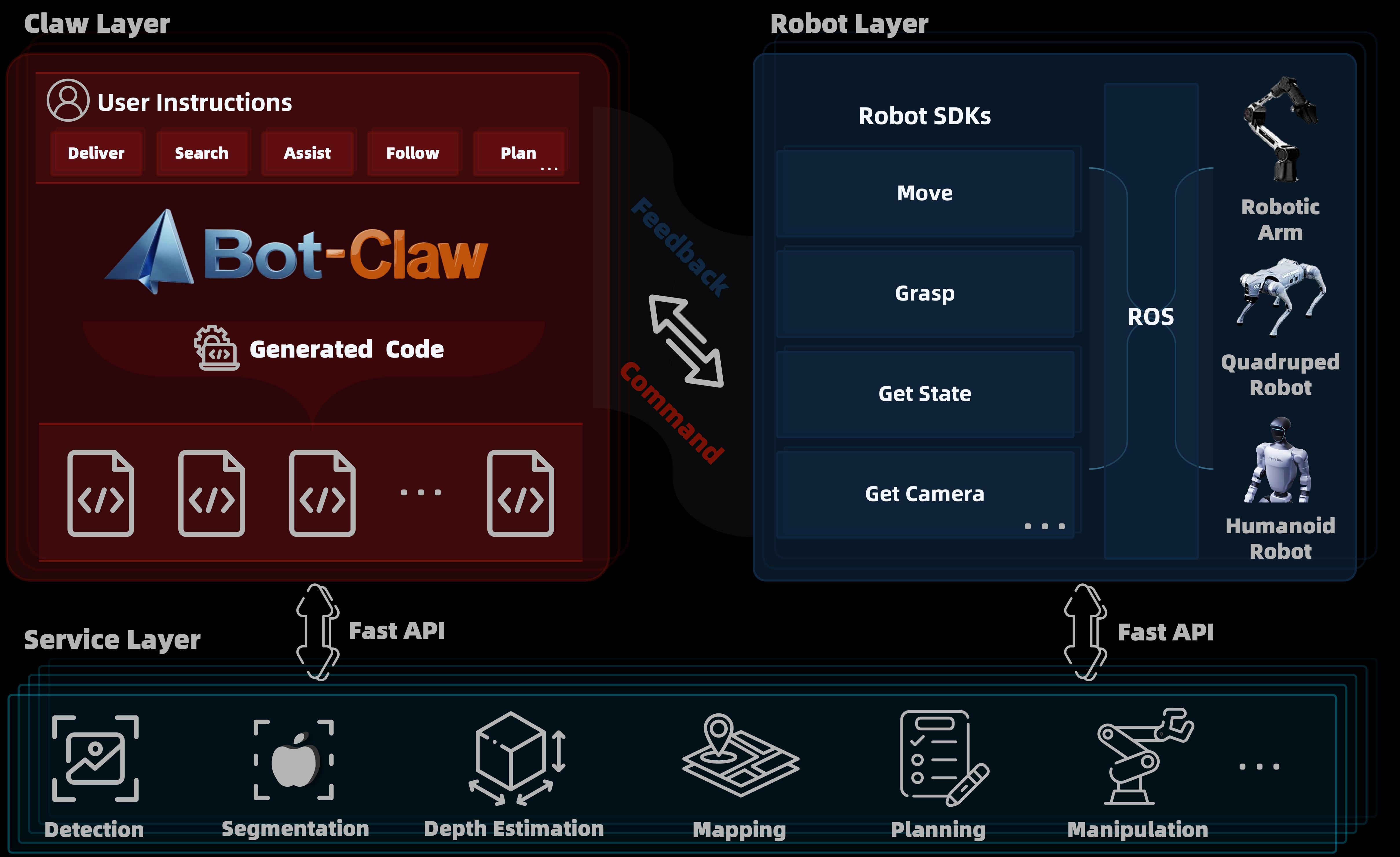
Additionally, ABot-Claw employs a two-tier design of “cloud brain - edge response,” balancing intelligence depth with execution reliability. In terms of scheduling, this architecture supports parallel collaboration and task relay among various heterogeneous robots, automatically continuing tasks in case of failures, achieving seamless transfer of task context and cross-form collaboration. This marks the evolution of robotic systems from “individual intelligence” to “systemic intelligence,” where robots are no longer isolated entities but intelligent network nodes that share memory, unify scheduling, and co-evolve.
ABot-Claw also pioneers a closed-loop feedback and correction mechanism, fully validating its robustness and generalization in complex scenarios such as ambiguous instruction understanding and cross-machine guidance.
With the global debut of Gaode Tutu, Gaode also announced the open-sourcing of the entire ABot system, a move that not only deeply embodies the core philosophy of “AMAP AI Inside” but will also reshape the research paradigm of embodied intelligence, accelerating the comprehensive arrival of the AGI era.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.